The AI Shepherd: Why the Most Important Role in AI Does Not Exist Yet
Every technology wave creates new job titles. The internet gave us webmasters. Big data gave us data scientists. The cloud gave us DevOps engineers. Each title sounded strange at first, then obvious in hindsight. We are at that inflection point again.
The question I keep circling back to is this: when AI agents are making business-critical decisions based on your data, who is responsible for making sure they reason correctly? Not the model provider. Not the prompt engineer. Someone inside your organization who understands both the facts in your data foundation and the probabilistic nature of the systems consuming them.
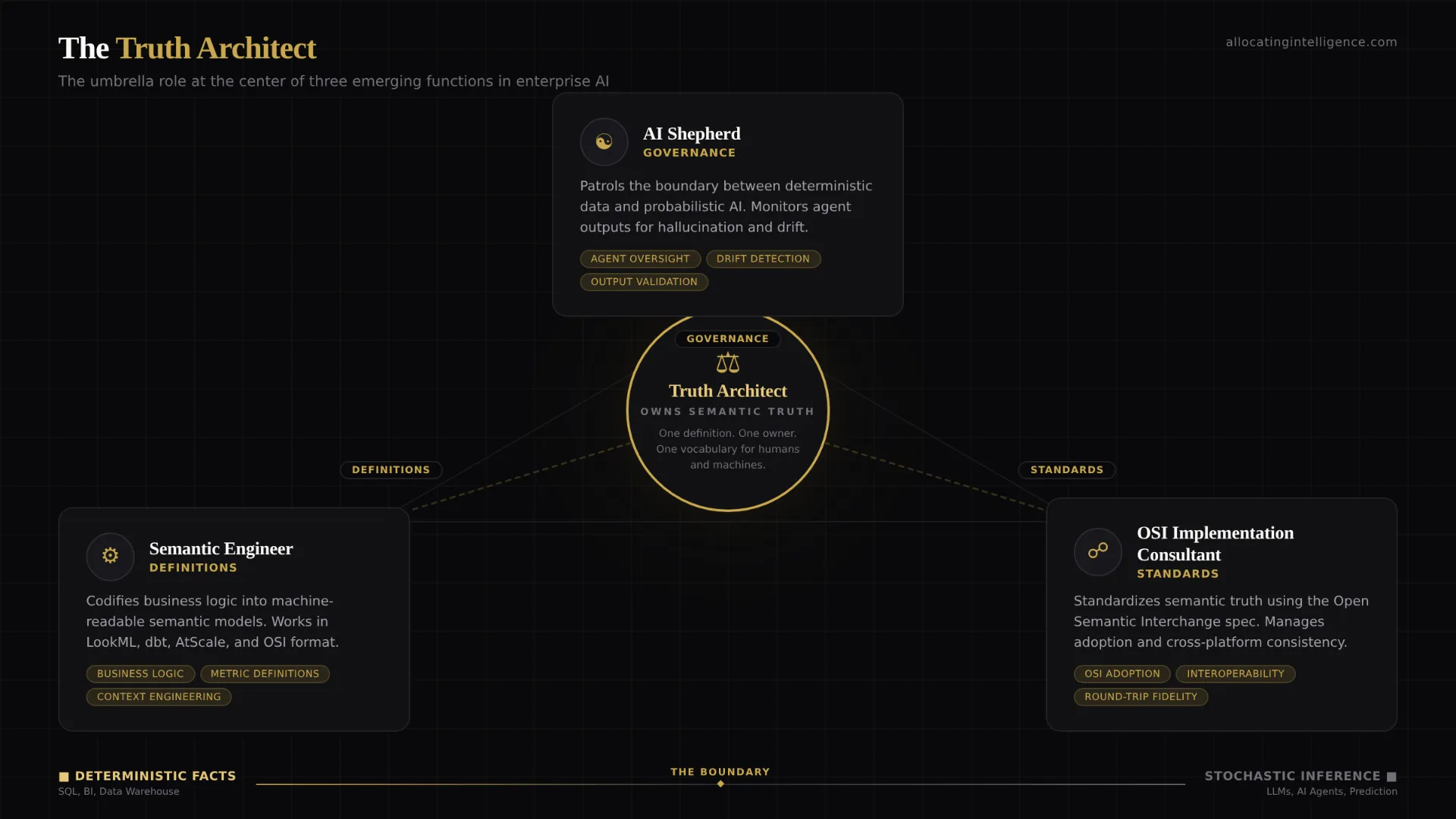
That role does not have an established name yet. But I have been thinking about it for a while, and I believe the answer is some combination of three emerging titles: the Semantic Engineer, the Truth Architect, and, the one I keep coming back to, the AI Shepherd.
The Data Architect Had One Job
For two decades, the data architect was the guardian of the enterprise data estate. They designed schemas, defined relationships, governed access, and ensured that the data flowing through pipelines was structured, documented, and trustworthy. Their world was deterministic. SQL queries returned the same results every time. Lineage was traceable. Every number had an address.
That world still exists. It still matters. But it is no longer sufficient.
The moment an AI agent sits on top of your data architecture, you introduce a fundamentally different type of system. The data architect builds the foundation of facts. The AI agent generates probabilistic outputs from those facts. One is deterministic. The other is stochastic. And somebody needs to stand at the boundary between those two worlds.
Facts vs. Stochastics: The Core Tension
This is the tension at the heart of enterprise AI in 2026. Your data warehouse is a system of record. It stores facts. Revenue was $4.2 million last quarter. You had 12,847 active users in March. Customer acquisition cost was $127. These are not opinions. They are deterministic outputs of governed queries against governed data.
Now hand that data to an AI agent and ask it to explain why acquisition cost increased. The agent will retrieve context from your warehouse, combine it with patterns from its training data, and generate a natural language explanation. That explanation might be brilliant. It might also be confidently wrong. And unlike a SQL query, you cannot simply re-run it and expect the same answer. The same prompt can produce different outputs on different runs because LLMs generate tokens by sampling from probability distributions.
The data architect ensures the facts are right. But who ensures that the stochastic system consuming those facts produces trustworthy outputs? Who monitors the boundary between what is known and what is inferred? Who intervenes when the agent hallucinates a metric that does not exist or misinterprets a business definition?
That is the job of the AI Shepherd.
The AI Shepherd
I use the word shepherd deliberately. A shepherd does not control the flock by issuing precise instructions to each individual animal. A shepherd sets boundaries, watches for straying, guides the group toward safe ground, and intervenes when something goes wrong. That is exactly what is needed at the boundary between deterministic data and probabilistic AI.
The AI Shepherd works alongside the data architect but has a fundamentally different focus. The data architect designs and governs the system of facts. The AI Shepherd governs how autonomous systems consume and reason about those facts. Their responsibilities include ensuring that AI agents operate from governed semantic definitions, monitoring agent outputs for hallucination and drift, maintaining the bridge between the deterministic data layer and the stochastic AI layer, and intervening when the boundary between fact and inference breaks down.
This is not prompt engineering. Prompt engineering is about crafting inputs. The AI Shepherd is about governing the entire interaction pattern between your data and the systems that reason about it.
The Semantic Engineer
If the AI Shepherd is the role that governs the boundary between facts and stochastics, the Semantic Engineer is the role that builds the bridge.
Context engineering is emerging as the most critical skill in data engineering for 2026. It means designing data systems that embed rich, machine-readable context alongside the data itself. This is more than writing documentation. It is encoding business meaning into infrastructure so that AI agents can consume it programmatically.
The Semantic Engineer builds and maintains the semantic layer. They codify metric definitions, govern business vocabulary, and ensure that every tool in the stack, from dashboards to AI agents, operates from the same set of definitions. They work in tools like LookML, dbt Semantic Layer, AtScale, or Omni. And increasingly, they work with open standards.
This is where things get interesting.
The Open Semantic Interchange and What It Makes Possible
In January 2026, the Open Semantic Interchange specification was finalized. OSI is a vendor-neutral, open-source standard for exchanging semantic model definitions across the entire data and AI ecosystem. It is backed by over 50 organizations including Snowflake, dbt Labs, Databricks, Salesforce, Atlan, AtScale, Collibra, ThoughtSpot, Qlik, and Mistral AI.
I spent time reading the core specification. What struck me is how directly it addresses the problem at the heart of this article.
The OSI spec defines a YAML-based format for describing semantic models: datasets, fields, relationships, and metrics. But the feature that matters most for the future of AI is the ai_context field. Every construct in the OSI spec, from the top-level semantic model down to individual fields and metrics, can carry AI-specific annotations: natural language instructions, synonyms, and example queries that help AI agents understand business meaning.
Consider what this enables. Today, when an AI agent needs to understand what "revenue" means in your organization, it has to guess based on whatever context is available. With OSI, the definition is encoded directly into the semantic model, along with machine-readable instructions for how to use it. The agent does not guess. It reads the governed definition, the synonyms, the example queries, and the relationship to other metrics.
OSI uses a hub-and-spoke architecture. Instead of building point-to-point connectors between every tool in your stack, you express your semantic model in OSI format once, and converters handle the translation to each vendor's native format. With N vendors, you need 2N converters instead of N times N-1. That is not just an engineering efficiency. It is an organizational shift in how semantic truth propagates across an enterprise.
The spec supports multiple SQL dialects (ANSI SQL, Snowflake, Databricks, MDX, Tableau) so that metric expressions can be tailored to each platform while maintaining a single source of truth for what the metric means. Custom extensions let vendors carry platform-specific metadata without breaking core compatibility. And the entire thing is governed by a Technical Steering Committee with representatives from Snowflake, Salesforce, dbt Labs, and the Apache Software Foundation.
The OSI Implementation Consultant
Here is my bet on a role that does not exist today but will within 18 months: the OSI Implementation Consultant.
Think about what happened when REST APIs became the standard for web services. A new category of professionals emerged who specialized in API design, integration architecture, and governance. The same thing happened with OAuth, with GraphQL, with Terraform. Every time an open standard takes hold, a consulting ecosystem grows around it.
OSI is following the same trajectory. The specification includes a four-phase adoption guide: Evaluate, Pilot, Expand, Govern. Each phase requires expertise that most organizations do not have internally. Inventory your semantic layer across all tools. Map the pain points where semantic fragmentation causes friction. Test round-trip fidelity between vendor formats. Integrate OSI validation into your CI/CD pipeline. Establish ownership models for semantic models. Implement review processes for definition changes.
This is specialized work. It requires deep knowledge of semantic layer tooling (dbt, LookML, AtScale), familiarity with the OSI spec and its converter ecosystem, understanding of data governance frameworks, and the ability to bridge the gap between data engineering teams and business stakeholders. That combination of skills is rare today. It will be in high demand as OSI adoption accelerates.
Three Roles, One Mission
The AI Shepherd, the Semantic Engineer, and the OSI Implementation Consultant are not three separate silos. They are three facets of the same mission: ensuring that the bridge between deterministic data and probabilistic AI is solid, governed, and trustworthy.
The Semantic Engineer builds the bridge by codifying business logic into machine-readable semantic models. The OSI Implementation Consultant standardizes that bridge across the organization using open standards. The AI Shepherd patrols the bridge, monitoring what crosses from the world of facts into the world of stochastic inference and intervening when something goes wrong.
The Truth Architect I wrote about previously sits at the center of all three. It is the umbrella role, the person who owns semantic truth across the entire stack. Whether an organization calls this person a Truth Architect, a Semantic Engineer, or an AI Shepherd will depend on where the emphasis falls: on definitions, on infrastructure, or on governance.
But the function is the same. Someone has to own the boundary between what is known and what is inferred.
Why This Matters for C-Level Leaders
If you are a CDO, CTO, or CPO making AI investments right now, here is the practical takeaway: you are building systems where deterministic facts and probabilistic inference coexist. Your data architects cannot do this alone. They are experts in the world of facts. You need people who understand the world of stochastics and, critically, the boundary between them.
Start by asking: who in your organization owns the semantic layer? If the answer is "nobody" or "it is shared across teams," you have a gap. That gap will widen as you deploy more AI agents.
Then ask: when your AI agent produces an output based on your data, can you trace it back to a governed definition? If the answer is no, you need a Semantic Engineer building that traceability into the infrastructure.
And finally ask: who is watching the agents? Not the infrastructure they run on. The reasoning they produce. Who catches it when an agent confidently cites a metric that does not exist in your semantic model? Who intervenes when probabilistic outputs drift from deterministic facts?
That is your AI Shepherd. The title might change. The function will not.
The data architect builds the world of facts. The AI Shepherd guards the boundary where facts meet inference. And the companies that invest in both will be the ones whose AI actually works.